MySQL灵魂拷问系列之MySQL基础拷问
1.MySQL有哪些存储引擎,有什么区别
mysql我们耳熟能详的就是两种存储引擎:Innodb、Myisam
1.1 Myisam

- 不支持事务、外键
- 从 物理存储角度 上看,Myisam属于 非聚簇索引,数据存在叶子结点(没有孩子的节点)上,叶子节点的data为数据的物理地址引用(索引文件和数据文件分开存储),,通过物理地址引用来找到具体的数据行。
- 适用于 少量插入、大量查询 的场景,以前做 大数据报表系统 的时候会用到,一次性大批量插入,接下来只是纯查询.不过现在基本已经不用myisam了(mysql扛不住,单表一般控制在500w)
1.2 Innodb
- 支持事务、外键
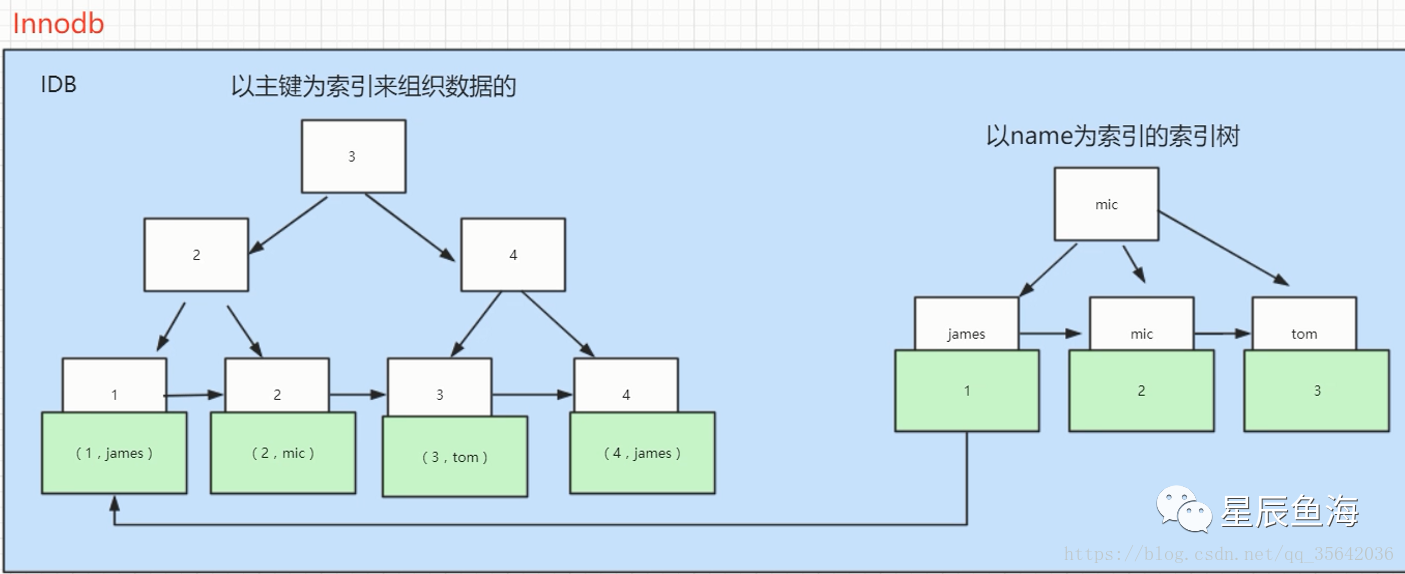
- 从 物理存储角度 上看,Innodb属于 聚簇索引,数据存在叶子结点(没有孩子的节点)上。如果是二级索引,则叶子结点存储的是主键,如果不止查询索引列,则需要再根据主键回表查询一次
- 目前来说,适用于大多数业务场景,无脑选即可
二级索引查找流程:先到二级索引的B+ Tree中根据name找到具体的叶子节点的data,data中存储的主键,根据主键再到聚簇索引(主键索引)中找到具体的数据行
1.3 Myisam和Innodb汇总比对图
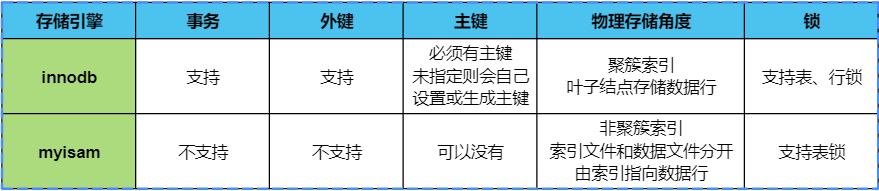
Innodb二级索引叶子结点存储的是 索引和主键,需要查询到主键后,去主键索引查询数据
2.为什么MySQL的索引要使用B+树而不是其它树形结构?比如B树?
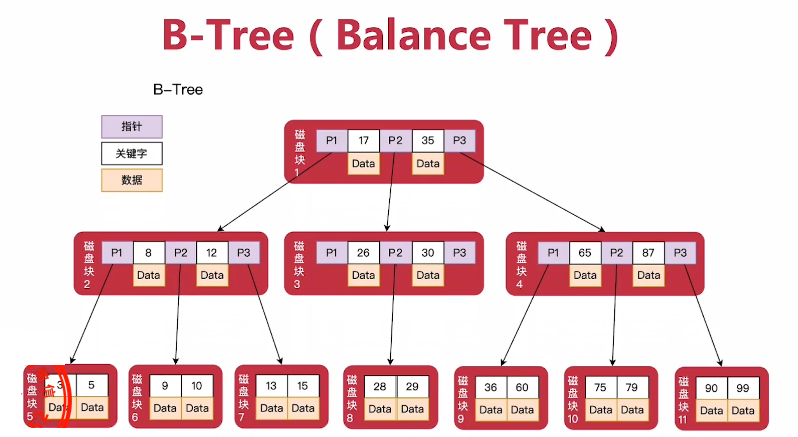
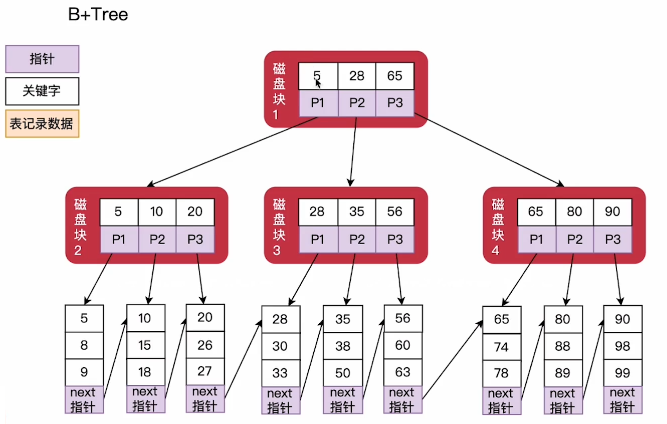
都属于多路搜索树
因为B树不管叶子节点还是非叶子节点,都会保存数据,如果要保存大量数据,只能增加树的高度,导致IO操作变多,查询性能变低
而B+树只有在叶子节点存储数据,非叶子节点只保存索引值
数据库对B+ Tree还进行了优化,让每个叶子节点末尾有一个 next指针 指向下一个叶子节点的数据,使得在做范围查询的时候效率更高
3.MySQL索引的使用规则
最左前缀匹配原则
假设表中只有A,B,C这三列的联合索引(A,B,C)
- 全列匹配
select * from table where A = 1 and B = 2 and C = 3
说明:完美地走这个联合索引
- 最左前缀匹配
select * from table where A = 1 and B = 2
说明:走联合索引
- 最左匹配了,中间的值未匹配
select * from table where A = 1 and C = 3
说明:A走索引,C不走索引,会当作过滤条件,因为也走索引,所以在性能上也是可以接受的
- 未匹配最左匹配原则
select * from table where C = 3
说明:全表扫描,性能低,需要优化
- 前缀匹配
select * from table where A = 1 and B like “2%”
说明:like关键字 左边不能加 %
- 范围/函数查询
select * from table where A >= 0 and B = 2 and 函数(C) = 3
说明:A走索引,B不走索引,B作为筛选条件,C不走索引
索引的注意事项
- 单表索引数量不宜过多
- 类似于status、isValid这样的经常性重复的字段,创建索引意义不大
- 类似于网站这样前缀大致相同的字段,可以新建一个字段使用 crc32 函数对相同部分做hash,再对新字段创建索引
【参考链接】
1:InnoDB和MyISAM两者的对比

