计算机网络灵魂拷问系列之基础问答
【参考链接】:
1:有道云笔记-网络
1. 浏览器请求www.baidu.com的全过程大概是怎么样的?
1.1 DNS解析
根据输入的域名去当前设置的DNS服务器中查询该域名对应的ip地址
1.2 封装报文
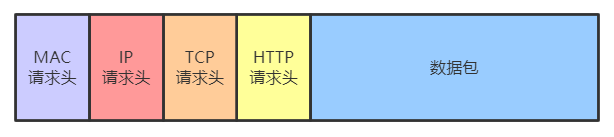
根据计算机网络的四层/七层模型,从上往下依次进行操作:
- 应用层:根据 HTTP协议 封装数据包,其中包括请求类型、请求地址、请求头、请求内容、HTTP版本等信息
- 表示层/会话层:数据加密,通过三次握手建立连接等
- 传输层:根据 TCP协议 把应用层封装的数据包再封装一层tcp协议的相关信息,设置 发送者/接收者的端口号 等信息
- 网络层:根据 IP协议 把网络层封装的数据包再封装一层ip协议的相关信息,设置 发送者/接收者的ip地址 等信息
- 数据链路层/物理层等:根据 以太网协议 把网络层封装的数据包再封装一层ip协议的相关信息,设置发送者/接收者的mac地址等信息(因为通过ip地址和子网掩码与操作后192.168.1这样的二进制信息不一致,所以接收者的mac地址设置的是 网关/路由器的mac地址 ,通过 广播 的方式层层网关下发送到目标服务器)
- 服务器 接收到多个数据包,根据数据包的序号排列再拼接成一个完整的数据包,对数据包依次进行处理解析出具体请求,转发请求给对应的应用(例如tomcat)上进行处理。应用 处理后返回响应数据包,按照原链路返回给请求浏览器,浏览器 解析渲染结果到页面上,再通过四次挥手断开连接
以太网默认数据包大小限制是 1500字节,如果ip数据包为5000字节,则会分为4个数据包发送(1500,1500,1500,500)
2. 画一下TCP三次握手/四次挥手流程图?什么是三次握手不是两次呢?
2.1 三次握手-建立连接流程
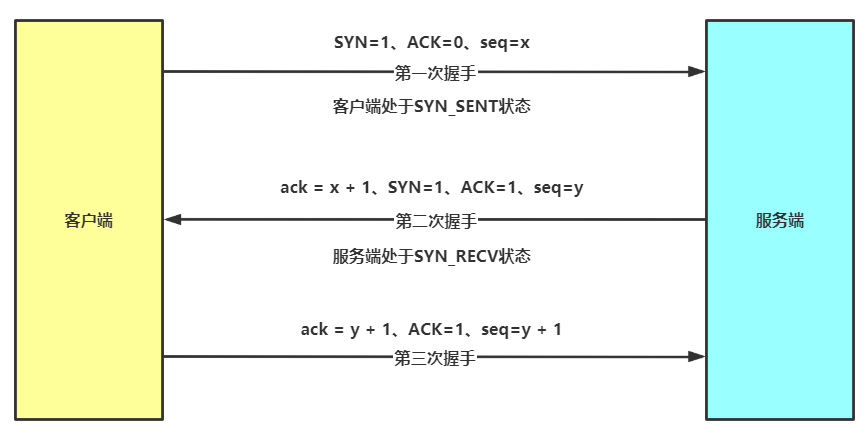
- 握手1:客户端发送建立连接报文,表示想与服务端建立起连接,自身进入发送状态
- 握手2:服务端返回确认报文,表示收到客户端握手1的请求报文了,并且成功开辟好资源等待连接,自身进入接收状态
- 握手3:客户端返回确认报文,表示收到服务端握手2的确认报文了,同时为了防止自己握手1时可能 多次发送握手1 的情况发生 会告诉服务端把其他连接的资源释放免得浪费
通过 传输层的tcp协议 建立网络连接的时候,其实就是走的三次握手的过程
通过根据约好的协议在 数据包请求头里设kv 来建立连接
三次握手的意义是为了 验证客户/服务端双方是否有收发数据的能力
首先,我让信使运输一份信件给对方,对方收到了,那么他就知道了我的发件能力和他的收件能力是可以的。
于是他给我回信,我若收到了,我便知我的发件能力和他的收件能力是可以的,并且他的发件能力和我的收件能力是可以。
然而此时他还不知道他的发件能力和我的收件能力到底可不可以,于是我最后回馈一次,他若收到了,他便清楚了他的发件能力和我的收件能力是可以的。
2.2 为什么是三次握手而不是两次呢
如果是 两次握手 的话,有一种情况会出现问题:
- 客户端 第一次发起握手1 ,可能由于网络抖动或者系统资源等原因 卡在半路上
- 客户端尝试 第二次发起握手1 ,这次发起成功,服务端发起第二次握手的同时会开辟资源,等待客户端发送数据。因为只有两次握手,所以这里代表此次建立连接成功
- 但是客户端 第一次发起的握手1 阻塞结束成功发送到了服务端,那么服务端也会继续发起握手2、开辟资源,而客户端因为 没有握手3来复位连接让服务端撤回开辟的资源 ,导致服务端资源被浪费
第三次握手作用:在发送了多次握手1时,会复位连接,保证服务端的资源不被浪费
2.3 四次挥手-断开连接流程
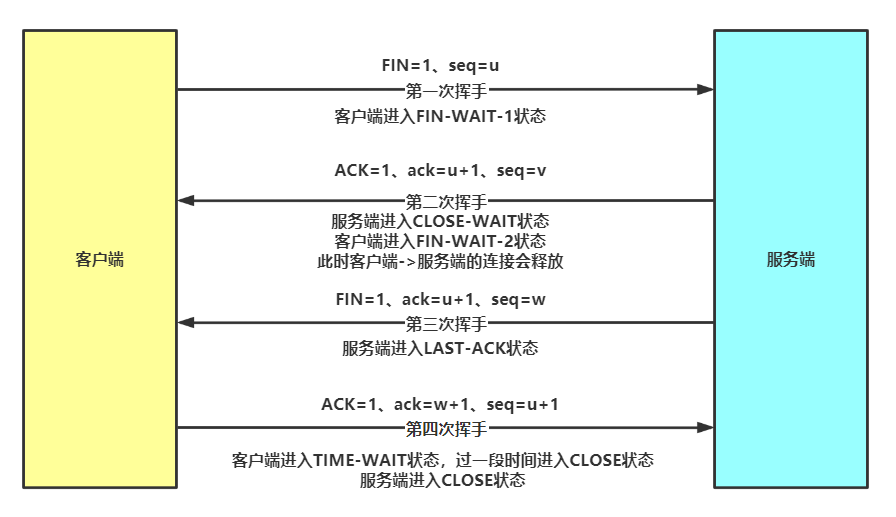
- 挥手1:客户端发送断开连接的报文,表示要关闭双方之间的连接,自身进入等待关闭连接的状态1
- 挥手2:服务端收到报文,进入等待关闭连接的状态,返回确认报文,这时客户端到服务端的连接就释放了,客户端收到报文时进入等待关闭状态2
- 挥手3:服务端发送连接释放报文,表示释放服务端到客户端的连接,自身进入连接关闭的最后确认状态
- 挥手4:客户端收到报文后发送应答报文,进入等待释放连接的状态,过一段时间进入连接关闭状态,
第一步:客户端C和服务端S说:我要断开和你的连接(C -> S)
第二步:服务端收到后返回表示同意,那么C -> S这条线就可以断开了
第三步:服务端和客户端说:我也要断开和你的连接(S -> C)
第四步:客户端收到后返回表示同意,那么等服务端这边东西全部给客户端传完之后,那么S -> C这条线也就断开了
3. HTTP的工作原理是什么
HTTP有1.0、1.1、2.0版本,底层都是在以太网协议、TCP协议、IP协议之上封装的HTTP协议,各个版本请求报文会有些许不同,但是基本相通的就有请求头、请求体、请求方法、响应状态码等
- HTTP1.0:在2000年之前,早期的网页只有文字,使用的是 TCP短连接 ,浏览器通过三次握手建立连接与服务器进行通信,接收到响应渲染到出来后,就会四次挥手断开连接(双方之间的连接不会太频繁)
- HTTP1.1:在之后的互联网迅猛发展的时期,往往网页都要加载很多图片、脚本等信息(CSS、JS),如果还是像HTTP1.0一样一次请求开辟断开一次连接则非常耗费资源和时间。所以HTTP1.1版本默认支持了 TCP长连接 。当浏览器通过三次握手和服务器建立连接之后不会马上关闭连接,来支持浏览器多次的请求,等待请求完毕再释放连接。
- HTTP2.0:HTTP1.1对同一时间同一域名的请求有限制,所以HTTP2.0支持 多路复用,基于一个tcp连接发送多个请求以及接收响应,来实现低延迟高吞吐
4. HTTP里的长连接是什么
HTTP本身没有长连接短连接之说,本质上是TCP的长连接和短连接,在HTTP1.0时,协议底层的TCP协议默认走的是短连接,HTTP1.1底层的TCP协议默认走的是长连接
- 短连接:每次请求响应后都会断开连接、释放资源
- 长连接:可以看成一个网页一个长连接,这个网页的多个请求都通过一个TCP连接来收到响应、获取资源,很长时间后,没有进行通信这个链接才被释放
长连接一般应用于聊天工具等这样的特殊场景
5. HTTPS的工作原理是什么
HTTP协议是 明文传输 的,中间商就可以拦截下来插入自己的广告或者篡改信息,来达到盈利的目的,这显然是不安全的

- 浏览器把自己支持的加密算法发送给网站
- 网站从中选择一套加密算法和hash算法,然后发送 证书 给浏览器(证书里含有网站地址、加密公钥、证书颁发机构)
- 浏览器校验证书合法性,如果合法一般浏览器地址栏旁边会出现一把绿色的锁。接着,浏览器会生成随机数密码P1,使用证书里的 公钥 对P1加密(非对称加密)保证P1的安全性;又对整个消息进行 hash算法 算出hash值H1;再使用P1对消息进行 对称加密,发送消息给网站
- 网站收到数据后,先使用 私钥 对消息解密取出密码P1,再对消息进行对称解密(使用P1),对消息进行hash,比对浏览器发送的hash值H1和自己计算的hash值,一致则说明未被篡改。成功建立连接
- 之后两者就使用密码P1进行hash加密、使用P1对消息进行对称加密的方式来通信