你真的了解线程池吗
1.new Thread的弊端
- 1:每次new Thread新建对象,性能差
- 2:线程缺乏统一管理,可能无限制的新建线程,相互竞争,有可能占用过多系统资源导致死机或者OOM
- 3:缺少更多功能,如更多执行、定期执行、线程中断
2.线程池的意义
- 1:重用存在的线程,减少对象创建、消亡的的开销,性能佳
- 2:可有效控制最大并发线程数,提高系统资源利用率,同时可以避免过多资源竞争,避免阻塞
- 3:提供定时执行、定期执行、单线程、并发控制等功能
- 4:让线程一定程度上可管理
3.线程池参数
线程池类:ThreadPoolExecutor,参数最完整的构造方法如下图
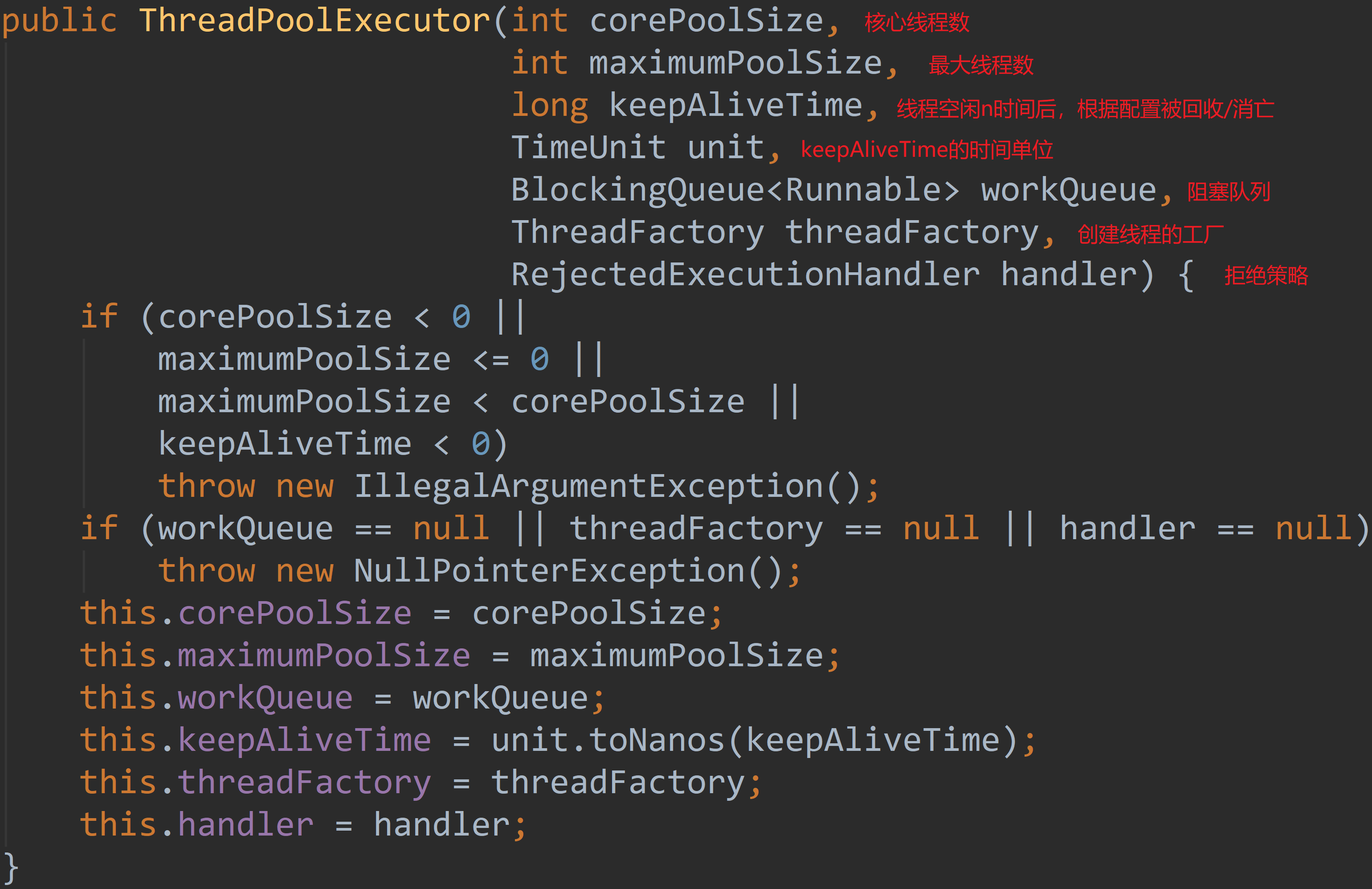
- 【coreThreadSize】:核心线程数量。类似公司的正式员工,在线程池公司中常年工作,除非设置了executor.allowCoreThreadTimeOut=true,否则线程一直运行着
- 【maximumPoolSize】:最大线程数=核心线程数 + 非核心线程数
- 【workQueue】:阻塞队列,当(很重要,会对线程池运行过程产生重大影响)
- 【keepAliveTime】:线程空闲时,最多保持多久时间后终止,默认情况下,指的是非核心线程的空闲时间,如果设置executor.allowCoreThreadTimeOut为true也表示核心线程的空闲时间
- 【unit】:keepAliveTime的时间单位
- 【threadFactory】:线程工厂,用于创建线程
- 【rejectHandler】:当拒绝处理任务时采用的策略
1.非核心线程数:被临时抽调来的线程池以外的系统线程。满足以下条件时:(1)当线程池的核心线程都在工作时(2)阻塞队列满了或者阻塞队列为SynchronousQueue缓存队列(3)最大线程数>核心数
当满足以上三个条件时,就会抽调池外线程(系统线程)来帮忙完成任务。任务完成后就会被回收
2.executor.allowCoreThreadTimeOut=true:表示核心线程也会像非核心线程一样,在保持多久keepAliveTime空闲后,该线程消亡被回收
阻塞队列如下:
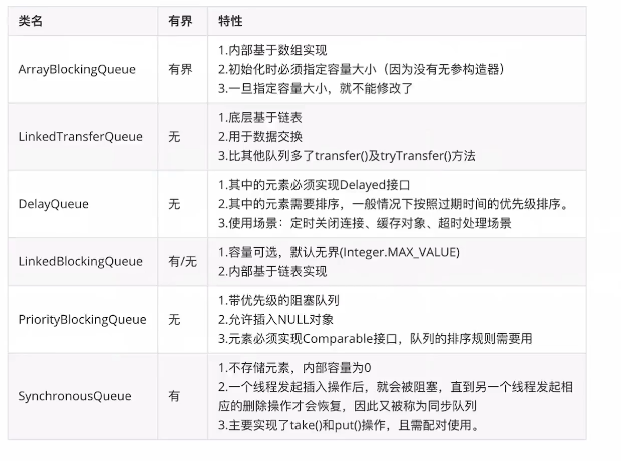
【LinkedBlockingQueue】:不初始化容量则为无界队列。当线程池开始使用时,最开始会创建核心线程,当线程数达到设置的核心线程数时,会进入排队,因为属于无界队列,所以不会创建非核心线程。缺点:系统消耗高,因为任务可以无限排队,当流量非常大时,就会占用很多的内存,严重时可能会导致内存溢出
【synchronousQueue】:无存储能力,一旦达到核心线程数之后,如果依然有比较多的任务进来,那么会尝试非核心线程,这时候maximumPoolSize要设置成比核心线程数更大的值才能生效
日常工作的时候,上述这些参数中,我们需要着重注意以下三个参数:coreThreadSize、maximumPoolSize、workQueue,为什么呢?看看线程池任务调度执行流程吧
4.线程池任务调度执行流程
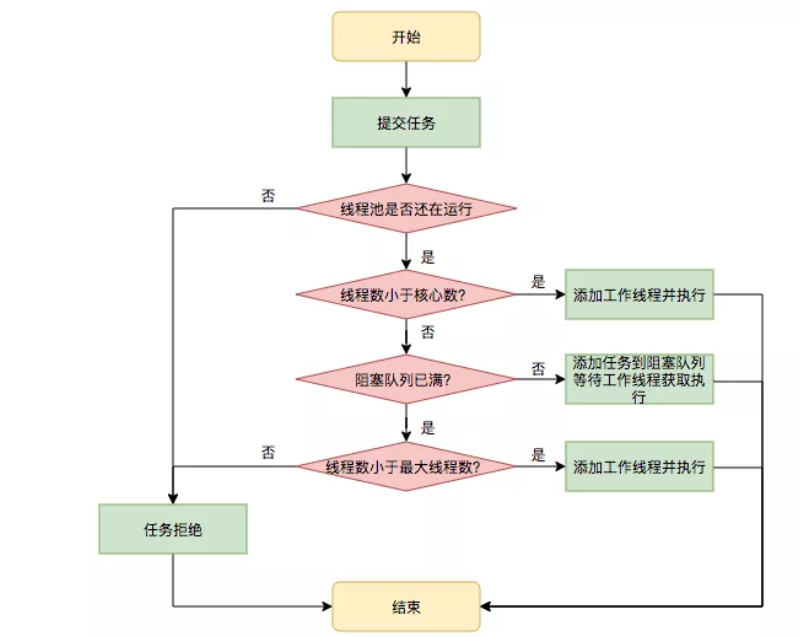
执行过程如下:首先检测线程池运行状态,如果不是RUNNING,则直接拒绝,线程池要保证在RUNNING的状态下执行任务。
1.如果 当前活跃线程数 < 核心线程数 ,则创建并启动一个线程来执行新提交的任务。
2.如果 当前活跃线程数 >= 核心线程数 且 线程池内的阻塞队列未满 ,则将任务添加到该阻塞队列中。
3.如果 当前活跃线程数 >= 核心线程数 且 当前活跃线程数 < 最大线程数 且 线程池内的阻塞队列已满 ,则创建并启动一个池外线程来执行新提交的任务。
4.如果 当前活跃线程数 >= 最大线程数 且 线程池内的阻塞队列已满 , 则根据拒绝策略来处理该任务, 默认的处理方式是直接抛异常。
可以看出,线程池任务调度执行流程中,息息相关的就是核心线程数、最大线程数、以及阻塞队列这三个参数,他们的配置很大程度上影响着线程池处理任务的性能
5.线程池拒绝策略
当线程池的任务缓存队列已满,并且线程池中的线程数目达到maximumPoolSize时,就需要拒绝掉该任务,采取任务拒绝策略,保护线程池。
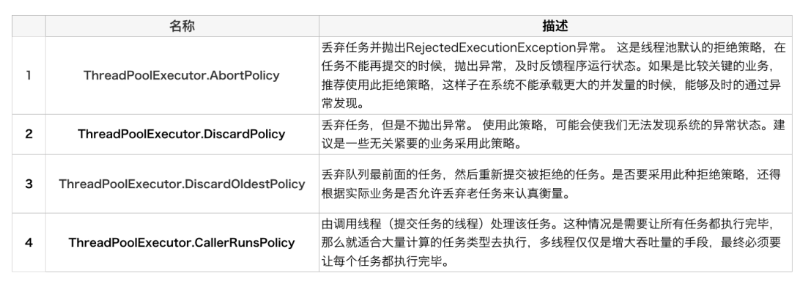
日常开发中,一般有两种使用拒绝策略的方式
- 采用 默认的拒绝策略AbortPolicy ,默认的拒绝策略可以及时的让系统抛出异常从而帮助开发人员定位问题
- 采用 自定义拒绝策略 ,通过持久化磁盘或者消息队列的方式,把被拒绝的任务交给负载相对较低的服务器处理,保证 任务能100%被处理
6 线程池使用场景
6.1 场景一:侧重于高吞吐能力
当我们需要统计报表时,比如统计汇总各区域数据之后进行处理、生成报表。这种场景相对于相应数据,我们更关注于如何使用系统有限的资源,尽可能在一定的时间内完成更多的任务,也就是保证充分利用且不浪费系统资源。
这时候我们应该设置一定容量的阻塞队列,并且根据系统参数配置核心线程数和最大线程数,减少线程间切换开销
阻塞队列:LinkedBlockingQueue(指定容量),有界的阻塞队列
线程数:最大线程数 = 核心线程数 ,一般设置为CPU核数+1,+1的目的是防止CPU空跑
【例子】:CPU为6核心6线程,则核心线程数为7,最大线程数为7,LinkedBlockingQueue阻塞队列容量为100
/**
*【线程池常用场景一】:
* 阻塞队列为LinkedBlockingDeque有界阻塞队列(指定容量了),一般最大线程数和核心线程数相等
* 比如以下例子中,核心线程数为6,最大线程数为6
* 所以需要执行10个线程时,6个核心线程都在运行,会把接下来需要执行的任务存放到阻塞队列中
* 等线程执行完毕后,再去队列中获取任务继续执行
*【结果】:2个3s后 10个任务执行完毕
*【工作应用】:
* 适用于实时性不会很强的业务解耦场景、比如异步发送通知、短信、异步生成报表等
*【优点】:吞吐量高
*【缺点】:在系统繁忙时,不保证实时性
* @param args
*/
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(6,
6,
5,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(100),
new NamedThreadFactory("demo-threadPool-", false));
// 提交10个任务给线程池执行 每个任务sleep 3秒
for (int i=0;i<10;i++){
executor.execute(() -> ThreadUtil.sleep(3000));
}
// 每1秒循环一次 已完成任务达到10时 跳出循环线程池关闭
do {
ThreadUtil.sleep(1000);
log.info("【--------------------场景一--------------------】");
log.info("【当前活跃线程数】:{}", executor.getActiveCount());
log.info("【当前已经完成的任务数量】:{}", executor.getCompletedTaskCount());
log.info("【当前池中的线程数量】:{}", executor.getPoolSize());
BlockingQueue<Runnable> queue = executor.getQueue();
log.info("【阻塞队列包含任务数量】:{}",queue.size());
} while (executor.getCompletedTaskCount() != 10);
executor.shutdown();
}在执行10个线程时,核心线程都在运行,会把接下来需要执行的任务存放到阻塞队列中,等线程任务执行完毕后再去队列中获取新的任务继续执行
6.2 场景二:侧重于实时性 快速响应
当用户进入一个页面时,页面聚合了多个服务的功能,可能开发会为了缩短响应时间,使用线程池去并行执行任务。这时候线程池就不应该设置阻塞队列来影响响应速度了,相对应的,建议提高核心线程数和最大线程数来增加并行线程的数量
阻塞队列:SynchoronousQueue
线程数:最大线程数 > 核心线程数
【例子】:CPU为6核心6线程,则核心线程数为1,最大线程数为10,阻塞队列为SynchoronousQueue也(队列容量为0)
/**
* 【线程池常用场景二】:
* 阻塞队列为同步队列SynchronousQueue,不存储任务,一般与最大线程数搭配使用
* 比如以下例子中,核心线程数为1,最大线程数为10,最大线程数=核心线程数+非核心线程数
* 所以执行10个线程时,1个核心线程都在运行,会向系统借调线程(9个线程)来执行任务
* 【结果】:3s后 10个任务执行完毕
* 【工作应用】:
* 适用于不影响主流程快速返回结果,但是也需要线程能快速处理好任务的场景
* 比如我司的支付回调后启动设备
* 【优点】:能更快速的处理完任务
* 【缺点】:系统性能和线程池吞吐量会受到一定影响
* @param args
*/
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(1,
10,
5,
TimeUnit.SECONDS,
new SynchronousQueue<>(),
new NamedThreadFactory("demo-threadPool-", false));
// 提交10个任务给线程池执行 每个任务sleep 3秒
for (int i=0;i<10;i++){
executor.execute(() -> ThreadUtil.sleep(3000));
}
// 每1秒循环一次 已完成任务达到10时 跳出循环线程池关闭
do {
ThreadUtil.sleep(1000);
log.info("【--------------------场景二--------------------】");
log.info("【当前活跃线程数】:{}", executor.getActiveCount());
log.info("【当前已经完成的任务数量】:{}", executor.getCompletedTaskCount());
log.info("【当前池中的线程数量】:{}", executor.getPoolSize());
BlockingQueue<Runnable> queue = executor.getQueue();
log.info("【阻塞队列包含任务数量】:{}",queue.size());
} while (executor.getCompletedTaskCount() != 10);
executor.shutdown();
}需要执行10个任务,此时1个核心线程在运行,会从池外(系统)抽调线程来运行剩余任务
6.3 Spring TaskExecutor快速实现自定义线程池
Spring集成了一个开箱即用的线程池接口以及多种实现类,这里我们举例其中的ThreadPoolTaskExecutor
配置类:TaskExecutorConfig.java
@Configuration
public class TaskExecutorConfig {
/**
* 构建一个demo线程池
* 测试类在 TaskExecutorTest
* @return
*/
@Bean("demoTaskExecutor")
public TaskExecutor buildDemoExecutor(){
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// 设置核心线程数
executor.setCorePoolSize(Runtime.getRuntime().availableProcessors());
// 设置最大线程数
executor.setMaxPoolSize(Runtime.getRuntime().availableProcessors());
executor.setThreadNamePrefix("taskExecutor-demo-thread-");
// 设置队列容量 默认容量为Integer.MAX_VALUE 不建议设置为默认值 极端场景会导致OOM
// 容量大于0:LinkedBlockingQueue 等于0:SynchronousQueue
executor.setQueueCapacity(100);
return executor;
}
}测试/使用类:TaskExecutorTest
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest(classes={ThreadPoolDemoApplication.class})
public class TaskExecutorTest {
@Autowired
@Qualifier("demoTaskExecutor")
private TaskExecutor taskExecutor;
@Test
public void testTaskExecutor() throws InterruptedException {
taskExecutor.execute(() -> {
log.info("线程开始休眠");
ThreadUtil.sleep(3000);
log.info("线程休眠结束");
});
log.info("【测试异步线程池】");
Thread.currentThread().join();
}
}
可以看到,前面介绍的三个重要参数,我们都可以在配置类中指定,并且可以为线程池命名,可以说是非常方便了
7.JUC之Executors类(强烈不推荐使用)
java.util.concurrent包中为开发者提供了快速创建线程池的方法,如图:
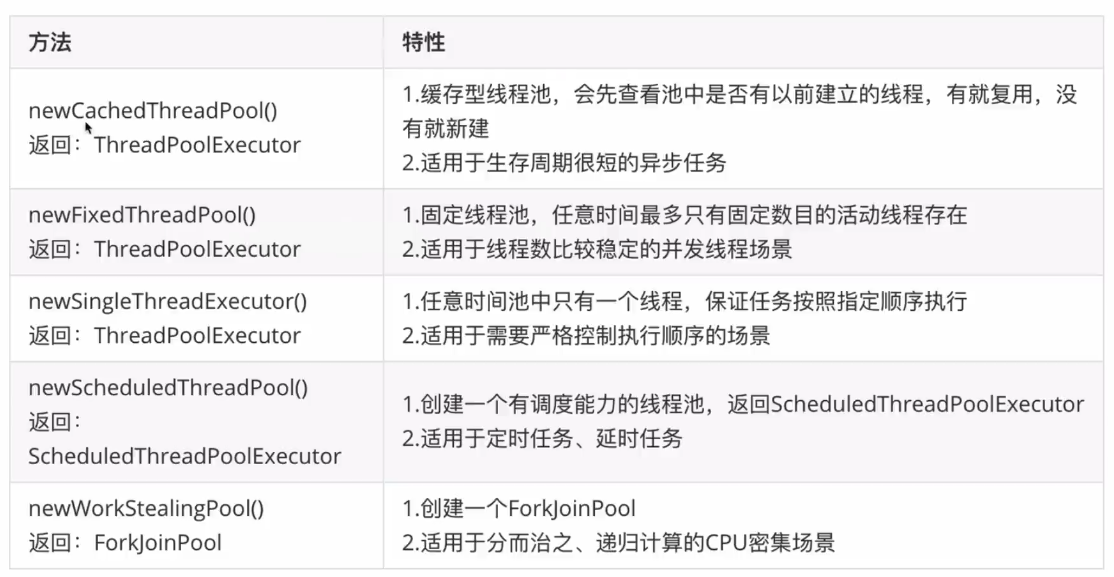
使用这种快速创建线程池的方法虽然极为省事快捷,但是不利于开发人员进一步了解线程池相关知识,也带来了隐患。
- 1:FixedThreadPool 和 SingleThreadExecutor : 允许请求的队列长度为 Integer.MAX_VALUE,可能堆积大量的请求,从而导致 OOM。
- 2:CachedThreadPool 和 ScheduledThreadPool : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致 OOM。
8.线程池技巧与调优
8.1 任务类型合理配置线程个数
(1)CPU 密集型任务 = N(CPU 核心数) + 1
这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
【适用场景】:数字计算、排序、挖矿等等
(2)IO 密集型任务 = 2N(CPU核心数)
这种任务应用起来,系统会用大部分的时间来处理 I\O 交互,而线程在处理 I\O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I\O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
【适用场景】:操作数据库、文件等
(3)混合型任务

详细计算可查看这篇博客:如何合理地估算线程池大小?
8.2 调优小技巧与Tips
线程池抉择
如果想要降低系统资源的消耗(cpu使用率,操作系统资源消耗,上下文切换开销),那么可以设置一个比较大的队列容量和一个比较小的线程池容量
如果队列经常堆积比较多的任务,并且业务方面需要加快处理速度时,可以适当加大maximumPoolSize,找一些池外线程(临时工)帮忙
Timer与ScheduledThreadPoolExecutor的区别
timer是单线程的,如果一个线程执行时间很长,会影响下一个执行线程,实际项目中尽可能用ScheduledThreadPoolExecutor,慎用Timer
线程池自定义命名小技巧
// guava
new ThreadFactoryBuilder().setNameFormat("my-thread-pool-%d").build()
// hutoolnew NamedThreadFactory("my-thread-pool-", false)ScheduledThreadPoolExecutor
继承了ThreadPoolExecutor,一般被用来当做延迟队列线程池使用,但是仔细查看他的构造函数可以发现,最大线程数maximumPoolSize都被设置成默认的Integer.MAX_VALUE,生产环境上容易造成OOM或者导致服务器性能下降,建议使用消息队列中的延迟队列代替
8.3 线程池参数动态化
业务与流量不会总是一成不变的,当初合理的配置可能也会在突发的巨大流量面前兵败如山倒,固定的线程池配置亦是如此,满足当时,却可能顶不住未来。为此,美团团队在博客中提到了线程池参数动态化的思路,非常值得精读!
9.线程池灵魂拷问
9.1 当线程池里的线程执行异常会发生什么?
一个线程出现异常不会影响线程池里面其他线程的正常执行,该异常线程不是被回收而是线程池把这个线程移除掉,同时创建一个新的线程放到线程池中。
异常线程是否会打印异常信息
- 调用方法为 execute() ,会打印出堆栈异常日志
- 调用方法为 submit() ,堆栈异常没有输出。但是如果业务需要获取线程返回值,调用了Future.get()方法时,可以捕获打印出堆栈异常信息。而很多时候我们可能并不需要获取执行结果,导致异常“被吃”,进而不触发告警信息酿成大祸,所以个人不建议使用
submit()。
两者在使用日志工具打印自定义日志都比较困难,所以个人更推荐结合jdk8的新特性CompletableFuture,搭配线程池一起使用,详情可以查看这篇文章:如何优雅地异步编程
9.2 如果线上突然宕机,阻塞队列中的任务怎么办?
阻塞队列中的所有任务会丢失
保证任务不丢失的思路
- 我们可以在提交任务前先进行落库处理,当宕机重启后,再拿出待处理的任务继续执行。
- 使用消息队列
9.3 你知道如果线程池的队列满了之后会发生什么事情吗?
关键在于 线程池当前活跃线程数 与 最大线程数 的对比
- 线程池当前活跃线程数 < 最大线程数,则线程池会抽调 池外线程(系统线程)来处理任务
- 线程池当前活跃线程数 >= 最大线程数,会根据线程池的拒绝策略来处理任务
保证任务100%被处理的思路: 自定义拒绝策略,把任务交给其他负载低的线程池进行处理,或者放入消息队列交给其他线程池处理 / 阻塞队列处理完毕后处理消息队列中的任务
10.线程池demo
如果想快速上手的话,可以试试我github上的demo,链接如下:
Java-Trivia:thread-pool-demo
【参考链接】:
1:如何设置线程池参数?美团给出了一个让面试官虎躯一震的回答
2:有的线程它死了,于是它变成一道面试题
3:Java线程池实现原理及其在美团业务中的实践
4:拿来即用的线程池最佳实践 JavaGuide
5:java线程池学习总结 JavaGuide
6:线程池的execute方法和submit方法有什么区别?

