Redis灵魂拷问系列之数据结构和单线程模型
【参考链接】
1:Redis 核心篇:唯快不破的秘密
2:Redis 6.0 新特性-多线程连环13问!
3:redis中文官方网站
4:redis三种高级数据结构
5:redis 学习(13)– BitMap
6:Redis 到底是怎么实现“附近的人”这个功能的呢?
[TOC]
1.说说Redis单线程模型,为什么单线程还有很高的效率
我们要明确的是:Redis 的单线程指的是 Redis 的网络 IO 以及键值对指令读写是由一个线程来执行的,对于 Redis 的持久化、集群数据同步、异步删除等都是 其他线程 执行。
根据官方数据,Redis 的 QPS 可以达到约 100000(每秒请求数),有兴趣的可以参考官方的基准程序测试《How fast is Redis?》,地址:https://redis.io/topics/benchmarks
一般的网络IO流程大致有以下事件
- listen 监听客户端请求
- accept 建立客户端连接
- receive 读取客户端请求
- write 写入/响应数据
如果是传统同步阻塞IO的话,在上述各操作未处理完毕时都会处于阻塞等待状态;而redis采用IO多路复用,不会阻塞在某一个特定的处理上,借此可以同时处理多个客户端的请求,提升并发性
IO多路复用
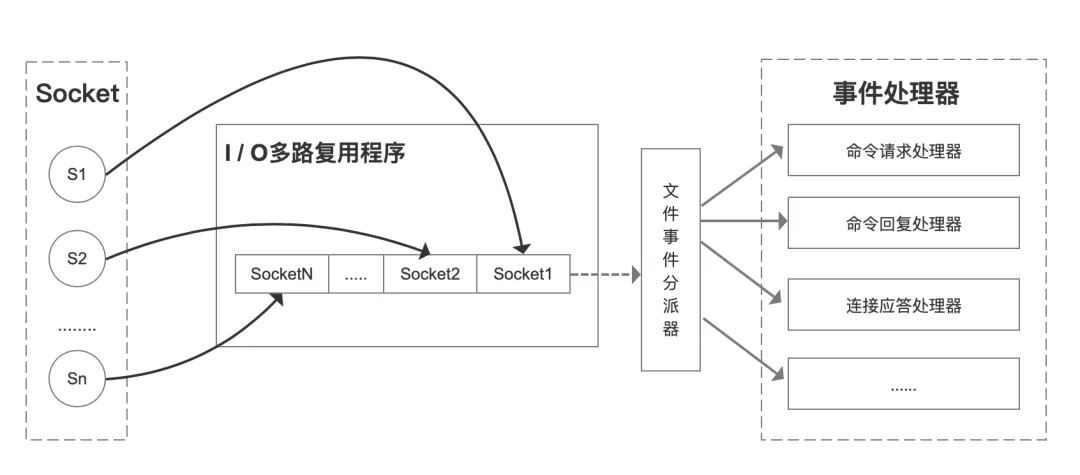
redis采用IO多路复用的方式,通过复用一个线程,来同时监听多个socket连接,根据标识符判断socket是否就绪(可建立连接、可读等),已就绪就将socket放入一个阻塞队列中。
由一个 文件事件分派器 依次不断地从队列中取出socket,再针对socket需要处理的事件类型来指派给对应的处理器
- 连接应答处理器:处理客户端连接请求
- 命令请求处理器:处理redis命令请求
- 命令回复处理器:redis命令请求由 命令请求处理器 处理完毕后关联至 命令回复处理器 来返回命令请求相关响应
为什么redis单线程模型效率也能这么高?
- 纯内存操作,属于纳秒级别
- 高效率的核心是使用了非阻塞的IO多路复用机制
- 单线程反而避免了多线程频繁切换上下文耗费资源的问题
2.那为什么redis 6.0又引入了多线程呢
严格来讲,redis 4.0之后都是用的多线程,而网络 IO 以及键值对指令读写是由单线程处理,对于 Redis 的持久化、集群数据同步、异步删除等都是 其他线程 执行。
redis 6.0默认关闭多线程,如若要开启,需要在 redis.conf 文件中 io-threads-do-reads yes,并且设置线程数 io-threads 4
官方建议:4核的机器建议设置为2或3个线程,8核的建议设置为6个线程,线程数一定要小于机器核数
开启IO多线程确实可以显著提升性能,但是如果要开启多线程,至少要4核的机器,且Redis实例已经占用相当大的CPU耗时的时候才建议采用,否则使用多线程没有意义。所以估计80%的公司开发人员看看就好
3.redis都有哪些基本数据结构?分别在哪些场景下使用比较合适?
3.1 String
简单的key/value结构
- 一般用来做 缓存、分布式锁 等,其中分布式锁一般涉及到的就是setnx以及expire等命令
string 命令笔记:redis string
3.2 Hash
类似map的结构
- 一般存放一些对象,比如用户信息等,可以指定修改对象其中的某个属性
hash 命令笔记:redis hash
3.3 List
属于 有序队列
- 一般可以用来保存 粉丝列表、评论列表 等,其中的lrange命令可以实现高性能的分页功能,很实用;
- 也可以用来当做 简单的消息队列 (lpush、rpop命令)使用,如果你的项目没有引入第三方消息队列组件,而依赖redis,不妨用redis做一个消息队列玩玩
list 命令笔记:redis list
3.4 Set
无需集合、自动去重
- 单机场景可以使用jvm中的HashSet去重,在多台机器上则可以直接使用redis set;
- 可以基于set做一些交集、并集、差集的操作,例如QQ中两人的共同好友(交集)
set 命令笔记:redis set
3.5 Zset(sorted set)
排序的set,既可以去重也可以排序,每个key写入时会给一个 分数score ,redis自动根据分数进行排序
- 可以做一些 访问量/点击量排行榜
zset 命令笔记:redis zset
4.那redis有没有哪些高级数据结构平常可以使用到呢?
4.1 bitMap 位图
bitMaps并不是真实的数据结构,其实是个 byte 数组,用二进制表示,只有 0 和 1 两个数字

127.0.0.1:6379> setbit login_2019_06_17 10000 1
(integer) 0
127.0.0.1:6379> setbit login_2019_06_17 1024 1
(integer) 0
127.0.0.1:6379> setbit login_2019_06_17 238 1
(integer) 0
127.0.0.1:6379> setbit login_2019_06_17 3434 1
(integer) 0
127.0.0.1:6379> bitcount login_2019_06_17
(integer) 4使用场景
- 用户签到、统计用户登录情况(活跃用户)、用户是否在线
- 实现布隆过滤器,避免推荐给用户已推荐的数据
布隆过滤器详情可以看看这篇文章:5分钟搞懂布隆过滤器
4.2 HyperLogLog
Redis HyperLogLog 是用来做 基数统计 的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
使用场景
- 统计用户日活月活
127.0.0.1:6379> pfadd login.2019_06_17 user1
(integer) 1
127.0.0.1:6379> pfadd login.2019_06_17 user2
(integer) 1
127.0.0.1:6379> pfadd login.2019_06_17 user3
(integer) 1
127.0.0.1:6379> pfadd login.2019_06_17 user4
(integer) 1
127.0.0.1:6379> pfcount login.2019_06_17
(integer) 4需要注意的是HyperLogLog的统计结果并不是一个精确的值,误差在0.81%左右,但是对于统计用户数这种场景来说足够了
4.3 Geo
这个功能可以将 用户给定的地理位置(经度和纬度)信息 储存起来,并对这些信息进行操作。
使用场景
- 附近的人

